If you’ve ever shopped on Amazon, you’ve used Your Orders. This feature maintains your complete order history dating back to 1995, so you can track and manage every purchase you’ve made. The order history search feature lets you find your past purchases by entering keywords in the search bar. Beyond just finding items, it provides a straightforward way to repurchase the same or similar items, saving you time and effort.
Various features across Amazon’s shopping experience, such as Rufus and Alexa, use order history search to help you find your past purchases. Therefore, it’s important that order history search can locate your past purchased items as accurately and quickly as possible.
In this post, we show you how the Your Orders team improved order history search by introducing semantic search capabilities on top of our existing lexical search system, using Amazon OpenSearch Service and Amazon SageMaker.
Order history search uses lexical matching to find items from the entire order history of a customer that match at least one word of the search keywords. For example, if a customer searches for “orange juice,” the system retrieves all orange juice items as well as fresh oranges and other fruit juices the customer had previously ordered. Although lexical matching can provide a high recall of items with terms matching the search keywords precisely, it doesn’t work well for related or generic search keywords, like “health drinks” in this example.
Since the launch of Rufus, Amazon’s AI-enabled shopping assistant, a growing number of customers are experiencing a streamlined and richer shopping journey, including searching for their previous purchases with Rufus. Customers can now ask “Show me healthy drinks” without worrying about using lengthy, more precise terms like “kombucha”, “green tea”, and “protein shakes”. This makes the search experience more conversational and intent-based, presenting an opportunity to make item discovery more intuitive. For Rufus to answer order history searches with the same intuitive experience such as “Show me the healthy drinks I bought last year”, the underlying order history data store (“Your Orders”) needs semantic search capability to understand the underlying semantics of search keywords beyond the conventional lexical matching.
Implementing semantic search at our scale presented several technical challenges:
Semantic search is powered by large language models (LLMs), which are mostly trained on human languages. These models can be adapted to take a piece of text in any language they were trained in and emit an embedding vector of a fixed length, irrespective of the input text length. By design, embedding vectors capture the semantic meaning of input text such that two semantically similar text strings have high cosine similarity computed on their respective embedding vectors. For semantic search on order history, the input text subject to embedding generation and similarity computation are the customer search phrases and the product text of purchased items.
We divide our solution into two parts:
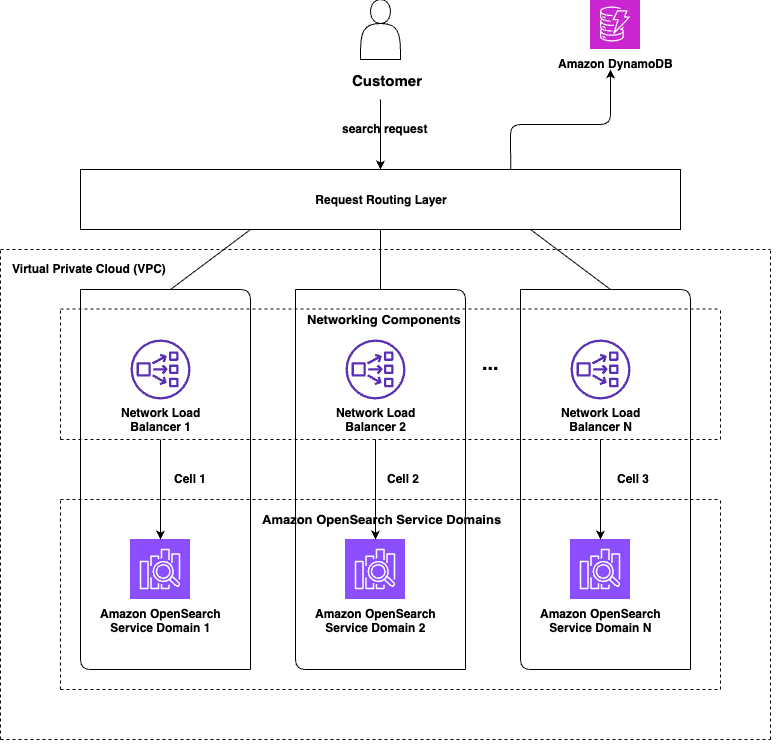
We used the cell-based architecture design pattern for improving our scalability and resiliency. A cell-based design entails partitioning the system into identical, smaller, self-contained chunks, or cells, which handle only a part of the overall traffic received by the system. The following diagram shows a high-level representation of a cell-based design for order history search.
Each cell serves a defined subset of our customers. Cells don’t need to communicate with one another to serve a customer request. Each customer is assigned to a cell and each request from that customer is routed to that cell. The OpenSearch Service domain in each cell holds data only for the subset customers that it is supposed to serve. The number of cells (N) and distribution of data among those cells depends on the business use case, but the goal is to achieve as even a distribution of data and traffic as possible.
The routing logic can be kept as simple or as sophisticated as the use case requires it to be. The cell assignment values can either be computed at runtime for each request, or they can be computed one time and written to a cache or persistent data store like Amazon DynamoDB, from where cell assignment values can be fetched for subsequent requests. For order history search, the logic was simple and quick enough to be executed at runtime for each request. Looking up cell assignment from a persistent data store is especially useful for cases where there is a risk of some cells becoming “heavier” than others over time. In such cases, it becomes easier to redistribute the heavy cell’s data by simply overriding cell assignment values for specific keys in the data store, instead of having to change the partitioning logic immediately, which might have an impact on data distribution across all the cells.
As the system’s load grows, the number of cells in the system can be increased to handle the additional traffic. Even without increasing the number of cells in the system, we can redistribute current data among the existing N cells by reassigning some keys from one or more heavily populated cells to different lightly populated cells to spread out the load more evenly across all the cells and make more efficient use of the infrastructure.
A cell-based architecture also helps make the system more resilient. For example, if we lose one cell, our capacity is diminished only by 1/N, instead of 100%. This arrangement can also be improved to reduce the capacity loss even further by assigning partitioning keys to two or more cells such that they get written to two or more cells. In such cases, loss of a single cell does not result in data loss.
Implementing semantic search for our order history search required several key decisions and technical steps. We began by evaluating the available embedding models, using the offline evaluation capabilities of Amazon Bedrock to test different models against our specific business domain requirements. This evaluation process helped us identify which model would deliver the best performance for our use case. After we selected our model, we needed to establish the infrastructure for generating embedding vectors. We containerized our embedding model and registered it in Amazon Elastic Container Registry (Amazon ECR), then deployed it using SageMaker inference endpoints to handle the actual vector computation at scale.
For the search infrastructure itself, we chose OpenSearch Service to implement our semantic search capabilities. OpenSearch Service provided both the vector storage we needed and the search algorithms required to deliver relevant results to our users.
One of our biggest challenges was updating our historical data to support semantic search on existing orders. We built a data processing pipeline using AWS Step Functions to orchestrate the workflow and AWS Lambda functions to handle the actual vector generation for our legacy data, so we could provide semantic search for all the records we wanted to.
The following diagram illustrates the high-level architecture.
Order history search uses an embedding model trained on Amazon-specific data. Domain-specific training is critical because the generated embedding vectors must work well for the business context to return quality results.
We used an LLM-as-a-judge methodology with Anthropic’s Claude on Amazon Bedrock to evaluate candidate models. Anthropic’s Claude received prompts containing anonymized item text and search phrases from customer order history, then filtered and ranked items by relevance. These results served as ground truth for comparison.
We evaluated models using standard ranking metrics:
This process helped us determine the best model.
Order history search has two key requirements:
Our approach involves using OpenSearch Service to retrieve all items for the customer who issued the search query, calculating relevance scores for each of them against the search phrase, sorting by score, and returning top K results. This provides comprehensive results coverage for each customer.
We used two OpenSearch Service features for efficient vector storage and search:
Hybrid search refers to combining the results of lexical and semantic search to benefit from the strengths of each. The hybrid query capabilities of OpenSearch Service simplify implementing hybrid search by letting clients specify both types of queries in a single request. OpenSearch Service runs both queries in parallel, merges their results, normalizes the relevance scores of the sub-queries, and sorts results by the provided sort order (relevance score by default) before returning them to clients.
This gives clients the best of both types of searches. For example, there are certain scenarios where the search phrase doesn’t make much sense semantically, like when customers search by their orderId values. Semantic search is not designed for such cases; these are best served using keyword matching.
The hybrid search functionality helped save implementation effort and potential latency increase for order history search.
After the infrastructure has been set up, newly ingested records are persisted with the relevant embedding vectors and support semantic search on those records. However, when customers search, they typically search for products they had purchased earlier. Therefore, the system might not help improve customer experience much unless the older records are updated to include the relevant embeddings. The approach to populate this data depends on the scale of the problem at hand.
Our final step was to release the change to clients in a manner such that the impact of any potential problems is as small as possible. There are multiple ways to do that, including:
The following are some examples of customer interactions with Rufus that required Rufus to query the respective customer’s order history to answer their question and give them the required pieces of information.
The following screenshots show how semantic search picks up wooden spoons for a “sustainable utensils” query and different kinds of chargers despite not having the keyword “charger” in the title description, in the case of the wall connector.
The following screenshots show how semantic search picks up relevant results even though the title description doesn’t include the queried keywords.
The semantic search feature of order history search helped Rufus fetch them and show to the customers. Before semantic search, Rufus wasn’t able to show any results to customers for such queries.
Our solution resulted in the following key business impacts:
In this post, we showed you how we evolved Amazon order history search to support semantic search capabilities. This transition involved using cutting-edge AI technology while working within existing infrastructure limitations to develop solutions that avoided disruption and maintained SLAs during the feature upgrade. The implementation also involved backfilling, where billions of documents were processed at rates multiple times higher than normal ingestion to compute embedding vectors for previously purchased items. This operation required careful engineering and took advantage of the resilience OpenSearch Service offers even under extreme load.
Beyond the immediate implementation, this foundation enables continued innovation in search technology. The embedding vectors framework can incorporate improved models as they become available, and the architecture supports expansion into new capabilities such as personalization and multi-modal search.
You can get started with exact k-NN search today following the instructions in Exact k-NN search. If you’re looking for a managed solution for your OpenSearch cluster, check out Amazon OpenSearch Service.
Shwetabh is a Senior Software Engineer at Amazon with interests in distributed systems and machine learning. Outside of work, he’s an avid reader with a particular love for technical deep-dives and thought-provoking non-fiction.
Harshavardhan is a Software Engineer at Amazon. He is passionate about machine learning, with particular interest in information retrieval and distributed computing. Outside of work, he enjoys playing racquet sports and watching football.
Ayush is a Tech Leader at Amazon. He is a passionate builder with an experience of over 14 years and leads the Your Orders Search product. In his spare time, he enjoys watching cricket and playing with his toddler.







