Growing data volume, variety, and velocity has made it crucial for businesses to implement architectures that efficiently manage and analyze data, while maintaining data integrity and consistency. In this post, we show you a solution that combines Apache Iceberg, Data Build Tool (dbt), and Amazon EMR to create a scalable, ACID-compliant transactional data lake. You can use this data lake to process transactions and analyze data simultaneously while maintaining data accuracy and real-time insights for better decision-making.
Traditional data lakes have long struggled with fundamental limitations. For example, the lack of ACID compliance, data inconsistencies from concurrent writes, complex schema evolution, and the absence of time travel, rollback, and versioning capabilities. These shortcomings directly conflict with growing business demands for concurrent read/write support, robust data versioning and auditing, schema flexibility, and transactional capability within data lake environments. To address these gaps, modern solutions use ACID transactions at scale, optimized storage formats through Apache Iceberg, version control for data on Amazon Simple Storage Service (Amazon S3), and cost-effective, streamlined maintenance—delivering a reliable, enterprise-grade data lake architecture that meets both operational and analytical needs.
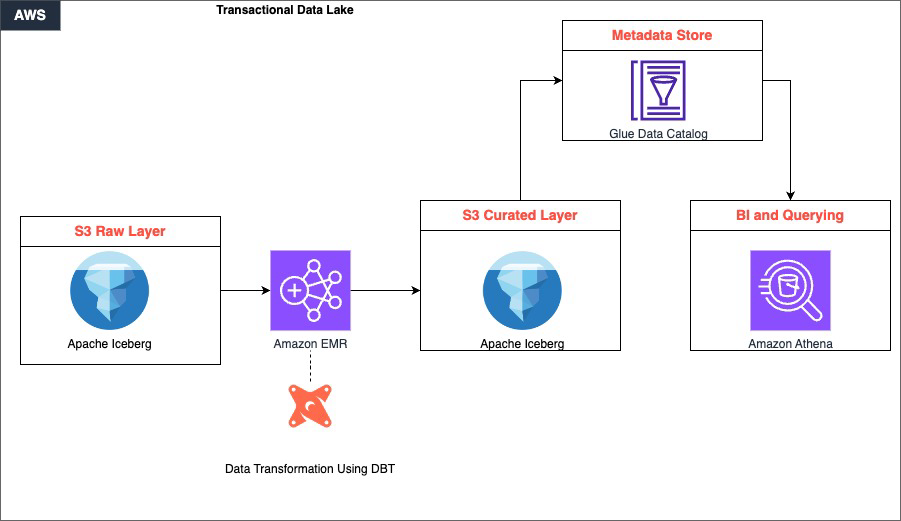
The solution is built around four tightly integrated layers that work together to deliver a scalable, transactional data lake.
Raw data is ingested and stored in Amazon S3, which serves as the foundational storage layer. This layer supports multiple data formats and enables efficient data partitioning through Apache Iceberg’s table format. This ensures that data is organized and accessible from the moment it lands. Then, Amazon EMR takes over as the distributed computing engine, using Apache Spark to process large-scale datasets in parallel, handling the heavy lifting of reading, transforming, and writing data across the lake.
Sitting within the processing layer, dbt drives the transformation logic. It applies SQL-based, version-controlled transformations that convert raw, unstructured data in the S3 raw layer into clean, curated datasets stored back in S3. This maintains ACID compliance and schema consistency throughout.
Finally, the curated data is available for consumption through Amazon Athena, which provides a serverless, one-time querying capability directly on S3. With this, analysts and business users can run interactive SQL queries without managing any infrastructure. Together, these components form a continuous pipeline: data flows from ingestion through distributed processing and structured transformation, ultimately surfacing as reliable, query-ready insights.
Amazon EMR is a cloud-based big data service that streamlines the deployment and management of open source frameworks like Apache Spark, Hive, and Trino. It provides a managed Apache Hadoop environment that organizations can use to process and analyze vast amounts of data efficiently.
Data Build Tool is an open source tool that data teams can use to transform and model data using SQL. It promotes best practices for data modeling, testing, and documentation, streamlining maintenance and collaboration on data pipelines.
Apache Iceberg is an open table format designed for large-scale analytics on data lakes. It supports features like transactions, time travel, and data partitioning, which are essential for building reliable and performant data lakes. By using Iceberg, organizations can maintain data integrity and enable efficient querying and processing of data.
When combined, these three technologies provide a powerful solution for building transactional data lakes. Amazon EMR provides the scalable and managed infrastructure for running big data workloads, dbt enables efficient data modeling and transformation, and Apache Iceberg provides data consistency and reliability within the data lake.
Before proceeding with the solution walkthrough, make sure that the following are in place:
Create the following JSON file with the following contents emr-config.json:
Run the following command on your AWS CLI, updating the preferred AWS Region:
The raw layer serves as the foundation of our data lake, ingesting and storing data in its original form. This layer is important for maintaining data lineage and enabling reprocessing if needed. We use Apache Iceberg tables to store our raw data, which provides benefits such as ACID transactions, schema evolution, and time travel capabilities.
In this step, we create a dedicated database for our raw data and set up tables for customers, products, and sales using Amazon Athena. These tables are configured to use the Iceberg table format and are compressed using the ZSTD algorithm to optimize storage. The LOCATION property specifies where the data will be stored in Amazon S3 so that data is organized and accessible.
After creating the tables, we insert sample data to simulate real-world scenarios. We use this data throughout the rest of the implementation to demonstrate the capabilities of our data lake architecture.
Update the respective bucket name in each create table bucket name from the previous step:
Setting up dbt involves installing the necessary packages, configuring the connection to the data warehouse (in this case, Amazon EMR), and setting up the project structure.
We start by creating a Python virtual environment to isolate our dbt installation. Then, we install dbt-core and the Spark adapter, which allows dbt to connect to the EMR cluster. The profiles.yml file is configured to connect to the EMR cluster using the Thrift protocol, while the dbt_project.yml file defines the overall structure of the dbt project, including model materialization strategies and file formats.
In this step, we implement dbt models, which define the transformations that we will apply to raw data. We start by configuring data sources in the sources.yml file, which allows dbt to reference raw tables easily.
We then create dimension models for customers and products, and a fact model for sales.
These models use incremental materialization strategies to efficiently update data over time. The incremental strategy processes only new or updated records, significantly reducing the time and resources required for each run.
The analytics layer builds upon dimension and fact models to create more complex analyzes. In this step, we create a daily sales analysis model that combines data from fact_sales, dim_customers, and dim_products models.
We also implement a customer insights model that analyzes purchase patterns across different Regions and product categories.
These analytics models demonstrate how we can use our transformed data to generate valuable business insights. By materializing these models as Iceberg tables, we make sure that they benefit from the same ACID transactions and time travel capabilities as our raw and transformed data.
The analytics layer introduces a fact_sales_analysis model that consolidates transactional sales data with customer and product dimensions to enable business-ready reporting. Built as an incremental model with a merge strategy, it efficiently processes data by deduplicating records using the latest inserted timestamp per order, enabling reliable downstream consumption without full table refreshes.
The customer_purchase_patterns model aggregates sales activity across customer Regions and product categories to surface revenue trends and buying behavior. Materialized as an Iceberg table in the analytics schema, it provides a performant and scalable foundation for customer segmentation, Regional performance analysis, and category-level revenue attribution.
This section demonstrates how to use Apache Iceberg’s time travel capabilities and transactional operations using actual snapshot data from our dim_customers table. We walk through querying data at different points in time and comparing changes between snapshots.
Let’s first look at current data:
Now, modify the raw layer data for customerid 201 and change the Region to East
Run the dbt model for dim_customers to sync the changes
Validate the data in curated layer for dim_customers dimension table
First, let’s fetch snapshots for customers dimension table in curated layer
Now, find the data state before and after the modification.
Data quality is a critical pillar of any reliable data pipeline. In this step, we define and enforce quality checks directly within the dbt project using schema-level test configurations. Rather than relying on one-time validation scripts, with dbt’s built-in testing framework, we can declaratively specify expectations on our models, ensuring that key fields remain unique, non-null, and consistent across the data layer before they reach downstream consumers.
The schema.yml file serves as the central contract for model integrity. Here, we apply generic tests on the fact_sales and dim_customers models to catch data anomalies early in the pipeline.
A well-functioning data pipeline requires ongoing maintenance to remain performant and auditable over time. This step covers two essential practices, table optimization to keep data storage efficient, and snapshot management to track historical changes in source data. Together, these procedures keep the pipeline reliable, cost-effective, and capable of supporting time-based analysis.
As data accumulates in Delta or Iceberg tables, small files and fragmented storage can degrade query performance. The optimize_table macro provides a reusable utility to run Databricks’ OPTIMIZE command on any target table, consolidating small files and improving read efficiency without manual intervention.
To maintain a historical record of customer data changes, we use dbt snapshots with a timestamp-based strategy. The customers_snapshot model captures row-level changes from the raw source layer and persists them in a dedicated snapshots schema, enabling point-in-time analysis and audit trails.
Observability is an essential aspect of any production-grade data pipeline. This step establishes logging and monitoring practices within the dbt project to track pipeline runs, capture errors, and support debugging. With structured logging enabled, teams gain visibility into model execution, test results, and runtime behavior, streamlining issue diagnosis and maintaining operational confidence.
The dbt_project.yml logging configuration directs dbt to write logs to a dedicated path and outputs them in JSON format. JSON-structured logs are particularly useful for integration with log aggregation tools and monitoring dashboards, enabling automated alerting and audit trail management.
With the pipeline fully built, tested, and maintained, the final step covers how to deploy and execute dbt models across different scenarios. Whether running a complete refresh, processing incremental updates, or validating data quality, these commands form the operational backbone of day-to-day pipeline management.
A full refresh rebuilds all models from scratch, reprocessing the entire dataset. This is typically used after significant schema changes, backfills, or when incremental state needs to be reset.
For routine pipeline runs, incremental updates process only new or changed data, significantly reducing compute time and cost. The following command targets specific models (dim_customers and fact_sales) allowing selective execution without triggering the full DAG.
After models are run, data quality tests defined in the schema configuration are executed to validate integrity across all models. This validates that constraints such as uniqueness and non-null checks are met before data reaches downstream consumers.
In this post, you learned how to build a transactional data lake on Amazon EMR using dbt and Apache Iceberg, from environment setup and modeling raw data, to quality enforcing, snapshot management, and incremental pipeline deployment. The architecture brings together the scalability of Amazon EMR, dbt’s transformation capabilities, and Iceberg’s ACID-compliant table format to deliver a reliable, maintainable, and cost-efficient data platform.
To get started, see the Amazon EMR documentation to deploy this architecture in your own environment. Whether you’re modernizing a legacy data platform or building a new analytics foundation, this stack gives you the flexibility to scale with confidence.
Umesh is a Data Analytics Lead Consultant at AWS ProServe, based in India. When not solving complex data challenges, Umesh is out on the trails — an avid runner and hiker who brings the same discipline and drive to fitness as he does to his work.
Amol is a Data Analytics Lead Consultant based in India. He helps customers to accelerate their journey to the cloud and innovate using AWS analytics services.







