AWS Glue Data Quality is a feature within AWS Glue designed to enhance trust in your data, facilitating better decision-making and analytics. This tool allows users to establish, monitor, and enforce data quality rules across data lakes and pipelines, automatically detecting anomalies and validating data against set standards.
With Terraform, an open-source Infrastructure as Code (IaC) tool from HashiCorp, you can effectively deploy AWS Glue Data Quality pipelines. Terraform enables teams to define and manage cloud infrastructure using a declarative language, promoting version control and collaboration while minimizing manual errors.
This article discusses two complementary methods for implementing AWS Glue Data Quality with Terraform:
Implementation Overview
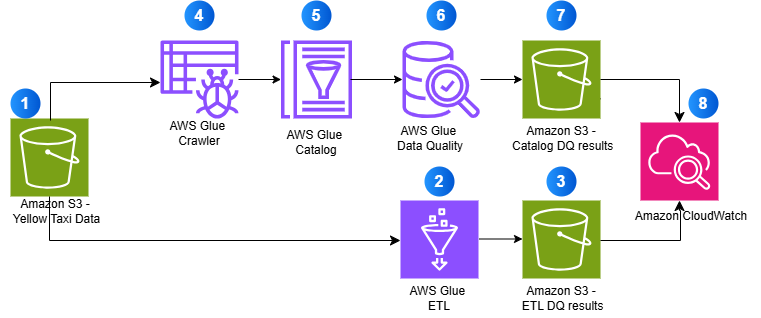
We will utilize the NYC yellow taxi trip data as a practical example to demonstrate data quality validation and monitoring capabilities. The pipeline will ingest parquet-formatted data from Amazon S3 and apply data quality rules to assess completeness, accuracy, and consistency.
ETL-Based Data Quality
This method validates data during the Extract, Transform, Load (ETL) job execution, making it suitable for early detection of issues.
Catalog-Based Data Quality
This approach validates data quality rules directly against AWS Glue Data Catalog tables, independent of ETL job execution.
The diagram below illustrates how these two methods work together to ensure comprehensive data quality validation:
Building the Pipeline
Follow these steps to set up your AWS Glue Data Quality pipeline using Terraform:
- Clone the GitHub repository.
- Review the Glue Data Quality job script
GlueDataQualityDynamicRules.pyin thescriptsfolder, which contains the relevant validation rules. - Configure your Terraform variables in the
terraform.tfvarsfile located in theexamplesdirectory. - Set up and authenticate your AWS CLI to interact with AWS services.
- Deploy your infrastructure using Terraform commands.
Executing Data Quality Validation
After deploying the infrastructure, validate data quality using both ETL-based and Catalog-based methods. Each method can operate independently or in conjunction:
- ETL-based validation captures issues during data transformation.
- Catalog-based validation checks data at rest in your data lake.
Both methods send metrics and logs to Amazon CloudWatch, enabling you to set alarms for quality score drops.
Cleanup
To avoid unnecessary AWS charges, delete all resources created during this tutorial. Ensure to back up any important data before executing the commands to destroy resources.
In conclusion, this guide demonstrated how to build a scalable data quality pipeline using AWS Glue Data Quality and Terraform. By implementing automated checks, organizations can maintain data integrity and enhance their analytics capabilities. This solution is adaptable for various data quality needs, ensuring reliable data for decision-making.
For further insights on AWS Glue Data Quality, consider reaching out to the authors:
- Viquar Khan, Senior Data Architect at AWS.
- Mahammadali S., Senior Data Architect at AWS Professional Services.







