This article explores how to significantly enhance inference performance by utilizing Intel Advanced Matrix Extensions (AMX) on Amazon Elastic Compute Cloud (EC2) 8th generation instances. With AMX, users can achieve up to a 76% acceleration in workloads.
Many organizations find CPU-based inference to be a more viable option for their production workloads, taking into account factors like cost and operational complexity. As AI solutions become more widespread, optimizing performance on standard CPUs is crucial for managing long-term operational expenses.
According to IDC, global AI spending is projected to reach $632 billion by 2028, with inference costs making up a significant portion of these expenses. Deloitte forecasts that by 2026, inference will account for two-thirds of all AI compute, surpassing initial training costs.
Challenges in CPU-Based Inference
Matrix multiplication operations are at the heart of inference workloads, but they also create performance bottlenecks. Organizations face three main challenges:
- Balancing cost optimization with performance needs.
- Meeting real-time latency requirements.
- Scaling efficiently with fluctuating workloads.
Intel AMX addresses these challenges by accelerating matrix operations directly on CPU cores, making CPU-based inference both competitive and cost-effective.
AMX Features and Benefits
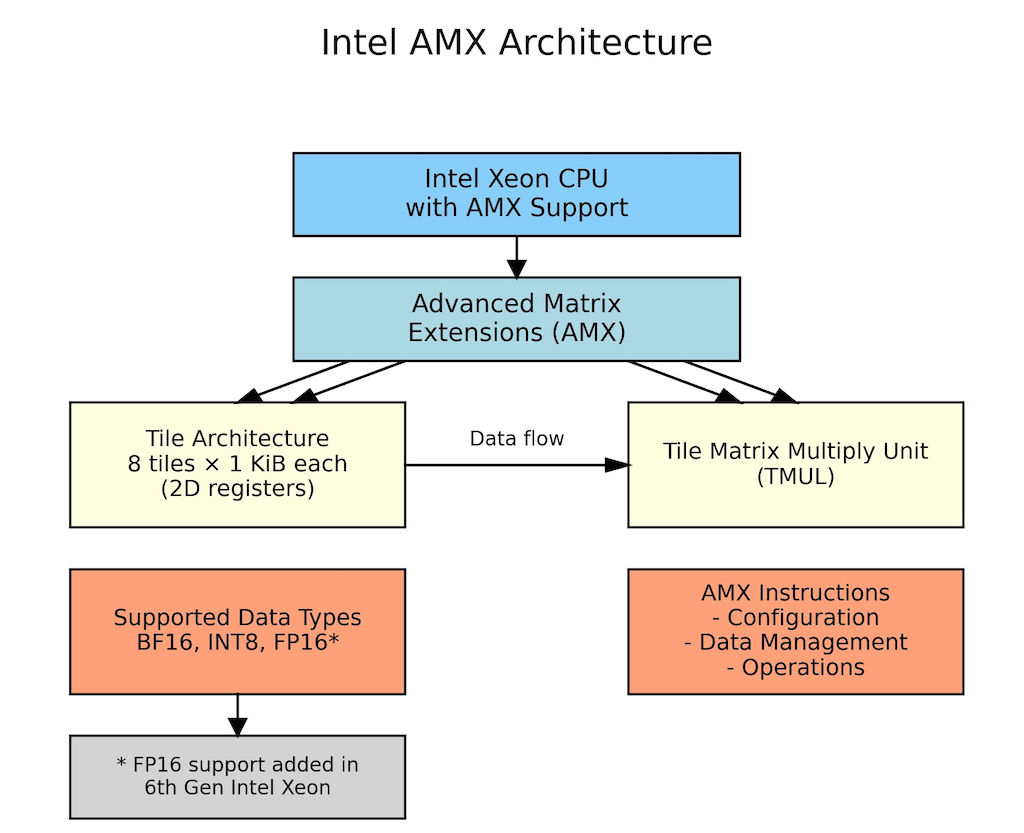
AMX supports various data formats such as BF16, INT8, and FP16, allowing users to match precision to their specific requirements. Introduced with 4th Generation Intel Xeon Scalable processors, AMX enhances computational efficiency by enabling processors to perform numerous operations per cycle.
Key benefits of CPU inference with AMX include:
- Batch processing and traditional ML: Suitable for content summarization and recommendation systems.
- Small to medium-sized models: Ideal for applications like fraud detection with models under 7B parameters.
- Variable demand workloads: E-commerce applications can scale CPU instances based on traffic.
- Complex business logic: Financial assessments and content moderation tasks benefit from CPU's mixed workload handling.
Implementation and Optimization
PyTorch, a widely used machine learning framework, includes optimizations for Intel AMX via oneDNN. Setting up requires installing dependencies and configuring environment variables for optimal performance.
To validate AMX's performance benefits, benchmarks were conducted across various language models. The tests demonstrated significant improvements in both latency and throughput when using AMX with BF16 precision.
Benchmark Results
Testing revealed that m8i instances outperform m7i instances, with latency reductions of 4-20% and throughput gains of 4-25%. AMX with BF16 optimization showed the most substantial impact, achieving up to 76% better performance compared to non-AMX configurations.
Conclusion
By leveraging Intel AMX on Amazon EC2 8th generation instances, users can realize substantial performance improvements for inference workloads. The benchmarks indicate up to 72% performance enhancements, making CPU inference a competitive option for various applications while also providing cost savings through improved resource utilization.
Key Takeaways:
- Immediate implementation of AMX optimizations can lead to significant speed gains.
- Start with BF16 optimization on existing workloads and explore INT8 quantization for further enhancements.







