Businesses generate vast amounts of unstructured data daily, including PDFs, images, emails, and customer feedback. Despite its potential for valuable insights, this data often remains underutilized due to challenges in extraction and searchability. Common examples like financial reports and legal documents often go unanalyzed, limiting data-driven decision-making.
To tackle these issues, this post outlines a method to automatically extract business context from unstructured documents, making them searchable and accessible through Amazon SageMaker Catalog. By integrating generative capabilities, you can enhance the discoverability of your data while maintaining governance.
Overview of the Solution
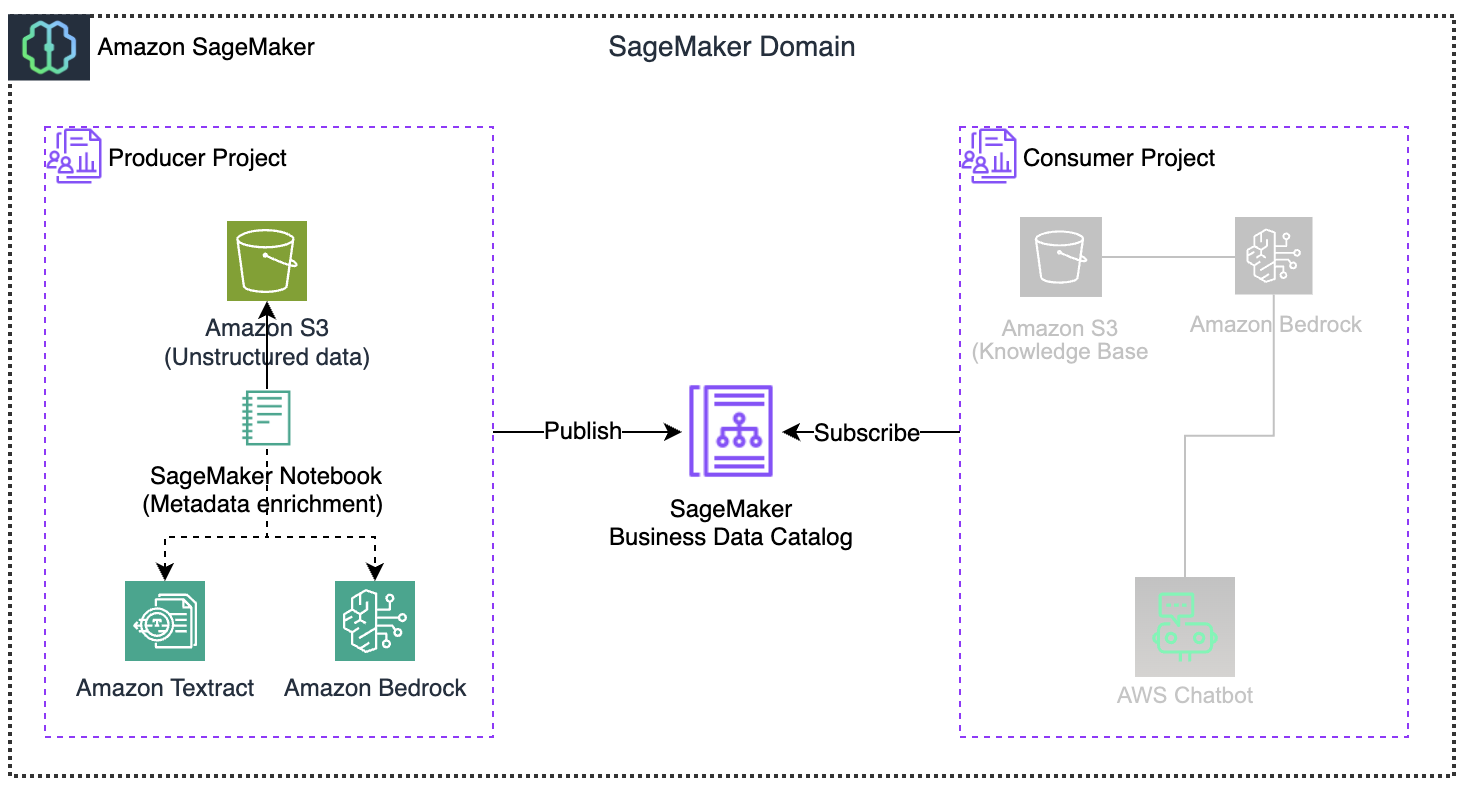
The solution transforms unstructured data into an interactive knowledge base using automated processing within the Amazon SageMaker environment. Here’s how it works:
- A pipeline processes raw documents, enabling user interaction with the Amazon SageMaker Catalog as the central hub.
- Generative features in SageMaker Catalog automatically develop business descriptions for structured data assets, enhancing documentation consistency.
- By incorporating S3 metadata, you can add context to extracted content, improving data cataloging.
Implementation Steps
To implement this solution, follow these steps:
- Download sample datasets to your local machine and upload them to your SageMaker Project S3 bucket.
- Log in to SageMaker Unified Studio and upload your files.
- Configure permissions for your project to access necessary services.
- Create glossary terms to classify sensitive and non-sensitive data.
Building Business Metadata
Utilize Amazon Textract and Amazon Bedrock to automatically build and curate business metadata. The process involves:
- Setting up connections to AWS services using Boto3 and initializing clients for Amazon S3, Textract, and Bedrock.
- Searching the S3 bucket for specific file types and processing them with Amazon Textract to extract text.
- Using the Anthropic Claude model to generate summaries of the extracted text.
- Classifying documents based on sensitivity and updating metadata accordingly.
Publishing and Discovering Data
After enriching metadata, republish the data to make it discoverable. Search for the published asset using keywords from the README sections. For example, you could search for high percent of ED visits.
Once found, select the asset to view its details, including rich business metadata and lineage information. With the asset published and metadata enriched, your data assets are now ready for use.
Conclusion
This post demonstrated how to transform unstructured data into valuable business assets through integration with AWS services. By leveraging Amazon Textract for text extraction, Amazon Bedrock for intelligent term identification, and Amazon SageMaker Catalog for metadata management, you can create a secure and governed framework for your data.







