Every minute of data processing pipeline downtime delays business decisions, stalls downstream analytics, drives revenue loss, and erodes stakeholder confidence. Teams that run Medallion Architecture pipelines—a common data lakehouse pattern where data flows through bronze, silver, and gold layers with increasing quality—face cascading failures that impact revenue-critical reporting and machine learning workloads. As you scale these multi-stage pipelines with Amazon Managed Workflows for Apache Airflow (MWAA), AWS Glue, and Amazon Redshift, troubleshooting failures becomes increasingly complex. When a mission-critical job fails, an engineer must sift through gigabytes of logs across interconnected systems. This means spending hours on incident investigations, examining execution timelines and resource metrics, and cross-referencing findings with Amazon CloudWatch and recent deployment changes to find the root cause. This requires deep familiarity with the underlying technologies, expertise not every team member has. When the right engineer is unavailable during off-hours, pipeline downtime extends and downstream consumers wait. The cycle of detect, investigate, fix, and repeat is costly and entirely reactive. A proactive operational model moves issue identification upstream, catching and addressing problems before they disrupt your data pipelines.
In this post, we show you how to diagnose multi-layer Medallion Architecture pipeline failures in minutes using AWS DevOps Agent with Apache Spark Troubleshooting Agent integrated as an MCP server.
AWS DevOps Agent is an autonomous investigation agent powered by AI that automatically diagnoses operational issues across your AWS environment. When a failure occurs, the agent independently gathers evidence from logs, metrics, and configurations across interconnected services, identifies the root cause, and delivers actionable remediation steps, all without human intervention. It integrates with your existing workflows through webhooks and delivers findings directly to communication channels like Slack. With AWS DevOps Agent, you can replace the reactive cycle of detect, investigate, fix, and repeat with autonomous, proactive troubleshooting. The agent acts as your always-on, on-call engineer, starting its investigation the moment a failure occurs, whether during business hours or in the middle of the night.
Apache Spark Troubleshooting Agent is an AI-powered, fully managed Model Context Protocol (MCP) server that data engineers can use to diagnose Spark application failures across Amazon EMR, AWS Glue, and Amazon SageMaker AI Notebooks using natural language. It automatically correlates Spark History Server data, distributed executor logs, and configuration patterns to identify root causes and deliver actionable recommendations. This removes hours of manual investigation across multiple consoles and log files.
The following sections walk through a common Medallion Architecture failure scenario and show how autonomous troubleshooting resolves it.
Consider this scenario: a gold layer AWS Glue job fails with “Missing data for not-null field.” The logs don’t reveal the actual problem. The root cause is a subtle data quality issue introduced upstream in the silver layer, a job that succeeded without errors. Without autonomous troubleshooting, you would manually trace data lineage across Amazon Simple Storage Service (Amazon S3), Amazon Redshift, and multiple AWS Glue job logs to find the source.
When integrated with the Apache Spark Troubleshooting Agent, AWS DevOps Agent identifies the gold layer Amazon Redshift write failure, traces it back to silver layer data corruption, and provides detailed root causes and actionable recommendations. The investigation typically completes within 3 to 5 minutes.
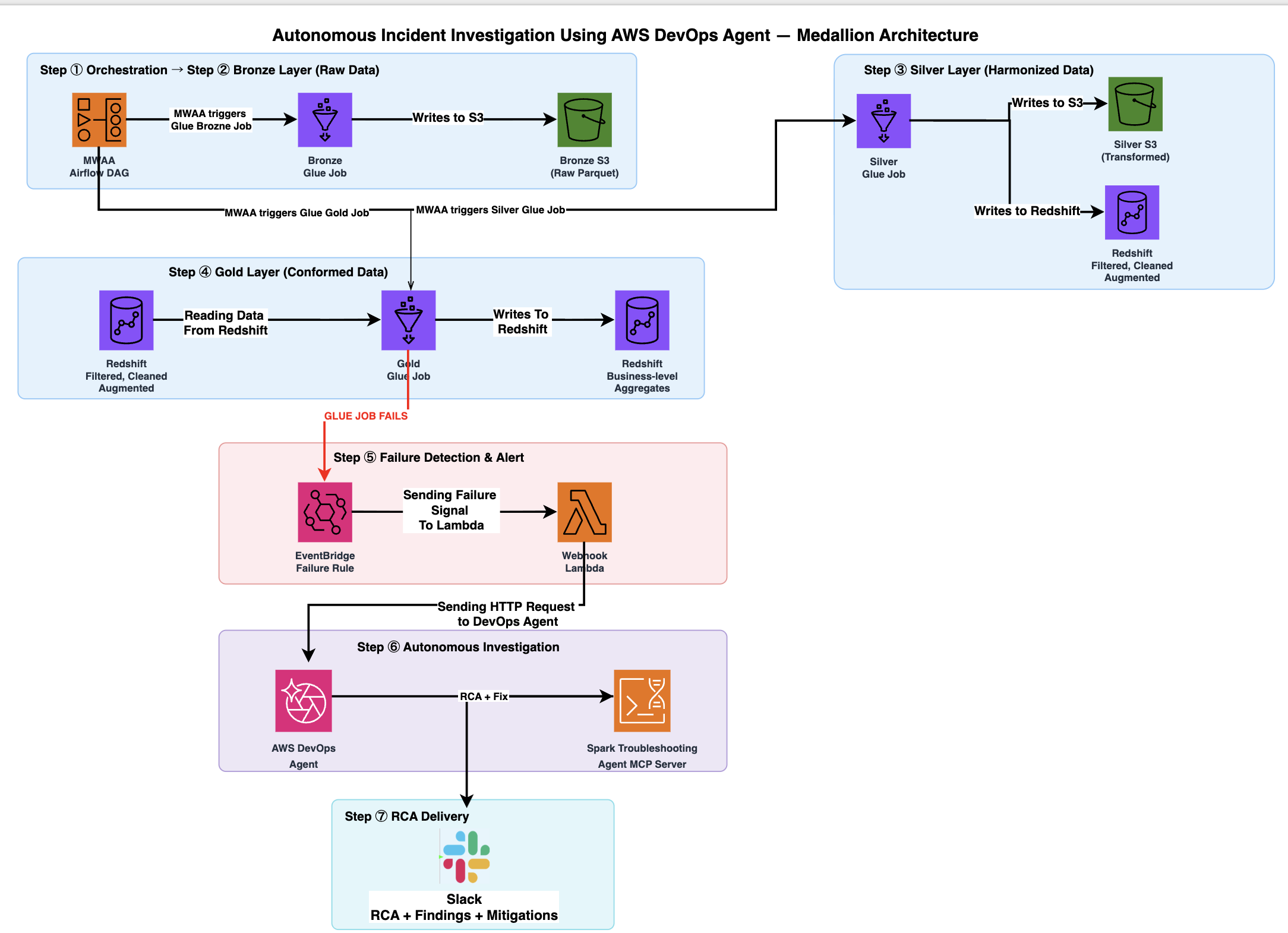
The following diagram shows the Medallion Architecture data flow across bronze, silver, and gold layers.
The architecture flow includes the following steps:
In the following sections, you deploy a three-layer Medallion Architecture pipeline that processes ecommerce order data. Complete the steps to get started with autonomous troubleshooting using AWS DevOps Agent.
Before you begin, verify that you have the following:
In this section, you configure AWS DevOps Agent to receive and investigate pipeline failure events. This involves three tasks: creating an Agent Space (your investigation workspace), optionally connecting a Slack channel for notifications, and generating a webhook endpoint that your pipeline uses to send failure alerts to the agent.
If you use Slack for internal communication, you can configure it to receive investigation results.
Note the Webhook URL and Secret Key for later. You provide them as parameters when you create the AWS CloudFormation stack.
The AWS CloudFormation template deploys the full Medallion Architecture pipeline. This includes an Amazon Virtual Private Cloud (Amazon VPC) with private subnets, an Amazon Redshift cluster (ra3.xlplus, single-node), and three AWS Glue jobs. It also creates an Amazon MWAA environment, Amazon EventBridge rules, AWS Lambda functions, and an AgentCore Gateway with Amazon Cognito OAuth authentication.
You can deploy the stack using one of two methods. Use Option A if you prefer a visual, guided experience through the AWS Management Console. Use Option B if you prefer working from the command line or need to integrate the deployment into a script or automation workflow.
Before you start, download the CloudFormation template from GitHub.
Option A: AWS Management Console (recommended)
Option B: AWS CLI
Replace the placeholder values:
Wait for the stack status to show CREATE_COMPLETE. In our testing, this took approximately 30–40 minutes.
After the stack is deployed, it creates an Amazon Cognito user pool with an OAuth 2.0 client for AWS DevOps Agent authentication. Retrieve the client secret using the command below. The --user-pool-id and CognitoClientId needs to be copied from the stack outputs.
Replace YOUR-REGION with the actual AWS Region value, and save this value for the MCP Server registration in the following step.
The Spark Troubleshooting MCP Server gives AWS DevOps Agent the ability to analyze Apache Spark event logs, executor metrics, and error stack traces from your AWS Glue jobs. By registering this server, you connect the agent to the diagnostic tooling it needs to autonomously investigate pipeline failures.
To register the MCP Server in AWS DevOps Agent, complete the following steps:
Now that you have completed the prerequisites, you can see AWS DevOps Agent in action. Go to the Amazon MWAA Airflow Environments UI and click on Open Airflow UI under Airflow UI. It will open in a new browser tab. In the Airflow console, locate and manually trigger the medallion_architecture_pipeline DAG.
The DAG runs three AWS Glue jobs sequentially:
With the components deployed and connected, the autonomous troubleshooting pipeline is ready to respond to failures. In this walkthrough, the silver layer job deliberately introduces data corruption to simulate a real-world data quality issue. This causes the gold layer job to fail, giving you the opportunity to see how AWS DevOps Agent responds.
As soon as the gold layer job fails, AWS DevOps Agent starts an autonomous investigation and uses the Apache Spark Troubleshooting MCP Server where needed.
Go to the AWS DevOps Management console and choose the medallion-troubleshooting under Agent Spaces. Next, select the Operator Access button. This will redirect you to Operator Console where you will see that the incident investigation automatically started in 1-2 minutes post Gold layer job failure.
After the investigation completes, AWS DevOps Agent presents its findings within the incident analysis. The results are organized into two sections.
The agent identifies the underlying cause of the failure, tracing the gold layer write error back to data corruption introduced in the upstream silver layer AWS Glue job.
On choosing Generate Mitigation Plan, the agent provides step-by-step remediation recommendations to resolve the issue and prevent recurrence.
Typically, within 3–5 minutes, the agent delivers a detailed investigation in Slack that includes root cause identification, upstream data lineage tracking, and an actionable recommendation.
You have deployed an autonomous troubleshooting pipeline for Medallion Architecture data pipelines. The pipeline runs using AWS Glue, Amazon Redshift, and Amazon MWAA, with AWS DevOps Agent providing autonomous investigation. The agent traced a gold layer Amazon Redshift write failure back to a silver layer data quality issue. This type of diagnosis would typically require hours of manual investigation by an engineer with deep expertise in Apache Spark, Amazon Redshift, and data pipeline architecture. AWS DevOps Agent completed it autonomously within minutes.
If you need human assistance, you can use the Ask for human support feature within AWS DevOps Agent to open a case with AWS Support, automatically populated with relevant investigation context.
AWS DevOps Agent autonomously investigates failures out of the box. You can enhance its diagnostic depth using Skills, a feature that provides the agent with domain-specific guidance tailored to your environment.
For Medallion Architecture pipelines, you can create Skills that instruct the agent to check for data type mismatches between pipeline layers when Amazon Redshift COPY errors occur, cross-reference silver layer data quality metrics with gold layer aggregation failures, or follow your internal runbook for escalating data quality issues to the upstream data engineering team.
To configure Skills, go to your Agent Space in the AWS DevOps Agent console and choose the Skills tab.
To avoid incurring future charges, delete the resources you created during this walkthrough promptly after you finish testing.
To clean up resources, complete the following steps:
Wait for the stack deletion to complete.
In this post, you deployed an autonomous troubleshooting pipeline for Medallion Architecture data pipelines using AWS Glue, Amazon Redshift, Amazon MWAA, and AWS DevOps Agent. The agent traced a gold layer Amazon Redshift write failure back to a silver layer data quality issue—a diagnosis that would typically require hours of manual investigation by an engineer with deep expertise across multiple services.
As your data pipelines grow in complexity, so does the challenge of diagnosing failures that span multiple layers and services. AWS DevOps Agent reduces your mean time to resolution by autonomously investigating incidents the moment they occur, whether during business hours or at 2 AM. Your on-call engineers spend less time sifting through logs and more time building reliable data infrastructure. By shifting from reactive firefighting to autonomous, proactive troubleshooting, you can improve pipeline reliability, protect downstream analytics and machine learning workloads, and maintain stakeholder confidence in your data platform.
To learn how to structure Agent Spaces for investigation accuracy, scope resource access, and use infrastructure as code to streamline deployment, see Best practices for deploying AWS DevOps Agent in production. To learn how to evaluate and choose the right lakehouse pattern for your needs, see Navigating architectural choices for a lakehouse using Amazon SageMaker. For more about Apache Spark Troubleshooting Agent, see Introducing the Apache Spark Troubleshooting Agent for Amazon EMR and AWS Glue.
Now that you have set up autonomous troubleshooting for your Medallion Architecture pipeline, consider exploring the following:
Mohammad is a Senior Technical Account Manager (TAM) at Amazon Web Services (AWS) with over 14 years of experience in Information Technology (IT). As a member of the Technical Field Community for Analytics team, he is a subject matter expert in Analytics services including AWS Glue, Amazon Managed Workflows for Apache Airflow (MWAA), and Amazon Athena. Sabeel provides strategic guidance and proactive technical support to enterprise and ISV customers, helping them optimize their data analytics solutions, build resilient architectures, and accelerate cloud adoption. With deep subject matter expertise, he enables organizations to build scalable, efficient, and cost-effective data processing pipelines.
Ishan is a Principal Cloud Engineer at AWS. He has worked in the Analytics domain for the last 17 years, now focused on data analytics, AI/ML operations, and proactive cloud optimization. He works with enterprise customers to design resilient data pipelines, automate incident response, and adopt GenAI-powered services and operational tools. He’s passionate about turning reactive support patterns into proactive, self-healing architectures.







