Organizations with lines of business operating across multiple AWS Regions increasingly run analytics workloads on globally distributed data. These organizations want to manage users and groups centrally, typically in the AWS Organizations management account and in a single Region, while still letting each line of business access data from the Region where its workloads run. Organizations should govern access based on the actual workforce user and their group memberships in the corporate directory.
With multi-Region support for AWS IAM Identity Center, organizations can federate workforce identities into a single organization instance in their primary Region. After you replicate this instance to additional Regions, member accounts running services such as Amazon Redshift or Amazon Athena in those Regions can integrate with IAM Identity Center locally, to resolve the same centrally managed users and groups.
This solution uses Trusted Identity Propagation (TIP), a capability that passes a user’s Identity Center identity and group memberships through a chain of AWS services. With TIP, when a user authenticates through Identity Center, that identity context flows to downstream services like AWS Lake Formation and Amazon S3 Access Grants. With this approach, you get consistent, identity-based access control without additional AWS Identity and Access Management (IAM) role configurations.
In Part 1 of this series, we showed how to simplify enterprise data access using the Amazon Redshift integration with Amazon S3 Access Grants. We demonstrated how to grant Amazon Simple Storage Service (Amazon S3) permissions to AWS IAM Identity Center users and groups using S3 Access Grants, and tested the integration using a federated user to unload and load data between Amazon Redshift and Amazon S3 within a single AWS Region.
In this post, we extend that solution across AWS Regions. We introduce a fictional company, AnyCompany Global, to illustrate how organizations with global operations can use AWS IAM Identity Center Multi-Region to set up consistent, identity-based access to Amazon Redshift and Amazon S3 Tables across Regions.
Specifically, we demonstrate:
We also show how to connect with your preferred SQL client.
AnyCompany Global is a retail analytics company with a centralized IT team and distributed analytics teams. They use the following personas:
AnyCompany Global has two AWS accounts:
The same IAM Identity Center user (Ethan) authenticates once and accesses data in Account B (us-west-2) using the same credentials and group memberships — you don’t need additional user provisioning because IAM Identity Center replicates identities to the secondary Region.
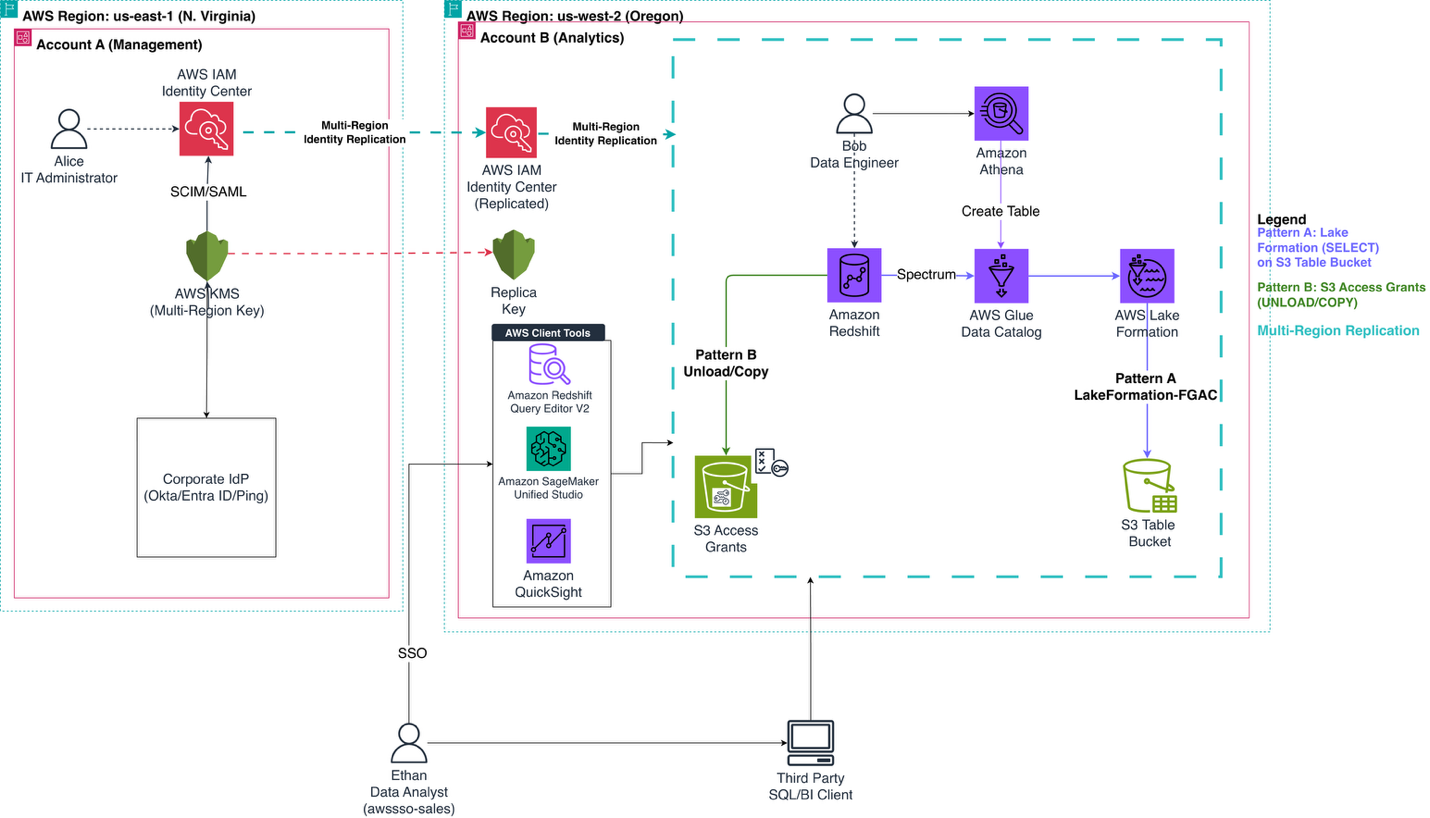
The following diagram illustrates the multi-account, multi-Region architecture. Account A (us-east-1) hosts IAM Identity Center, which replicates identities to us-west-2 where Account B runs the analytics workloads.
Figure 1: Multi-account, multi-Region architecture with S3 Access Grants, AWS Lake Formation, and IAM Identity Center.
This solution demonstrates two complementary data access patterns, both controlled by the end user identity:
The solution workflow includes the following steps:
The following sections walk you through enabling IAM Identity Center Multi-Region, configuring Amazon S3 Tables with Lake Formation in the secondary Region, testing both access patterns, and verifying the result with AWS CloudTrail. Start with the prerequisites, then complete each step in order.
You should have the following prerequisites already set up:
Note: Creating and using AWS resources in this tutorial incurs charges, including AWS Key Management Service (AWS KMS) keys, S3 table buckets, Amazon Redshift clusters, and Amazon S3 storage. See the cleanup section at the end of this post to avoid ongoing charges.
Alice performs this step in the management account (Account A, us-east-1). IAM Identity Center uses encryption at rest for identity data. To enable multi-Region, you must first create a multi-Region customer-managed AWS Key Management Service (AWS KMS) key and replicate it to the additional Region.
For detailed instructions, see Creating multi-Region replica keys.
Figure 2: Replica key configured for the additional Region.
A blue banner indicates that Identity Center is replicating your workforce identities, configuration, and metadata to the new Region. After the initial replication, the Replication Status column changes to Replicated. Your Identity Center endpoints in us-west-2 are now active.
For detailed instructions, see Add the Region in IAM Identity Center.
Figure 3: IAM Identity Center settings showing the multi-Region replica key added for us-west-2.
You’ve successfully replicated your Identity Center instance to the Oregon (us-west-2) Region. Your workforce identities are now available in that additional Region and can use the new AWS access portal endpoint.
To make sure AWS managed application (service provider-initiated) authentication redirect user to respective application, add the ACS URL for the additional Region so that the app contains both Regional ACS URLs.
In the following section highlighted in red, you can view all ACS URL information:
Figure 4: IAM Identity Center settings showing the View ACS URLs option.
Copy the respective ACS URL as shown in the following figure:
Figure 5: IAM Identity Center settings showing the ACS URLs for both Regions.
Use the following instructions to add the ACS URL for the additional Region in your Identity Center application in Okta:
Figure 6: Okta application for IAM Identity Center Sign-on tab to add ACS URLs.
Create a permission set in the management account to grant federated users console access to Amazon Redshift Query Editor V2 in the secondary Region (us-west-2). For more information about permission sets, see Permission sets.
After creation, assign this permission set to the relevant IAM Identity Center group (for example, awssso-sales) for Account B (us-west-2).
In this step, the data lake administrator (Bob) sets up Amazon S3 Tables with Lake Formation for fine-grained access control. He completes the following tasks:
Before creating S3 Tables resources, disable the default IAMAllowedPrincipals grants that Lake Formation applies to new databases and tables. By default, Lake Formation grants IAMAllowedPrincipals access to new resources, which means that standard IAM policies (rather than Lake Formation permissions) control access. For identity-based access through Trusted Identity Propagation, you need Lake Formation to be the sole arbiter of access.
The order matters. If you remove these defaults before registering the S3 Tables resource, Lake Formation will not apply IAMAllowedPrincipals to your S3 Tables catalog or its children. If you register the resource first, you need to manually revoke the IAMAllowedPrincipals grants from each resource.
Figure 7: Lake Formation Data Catalog settings with default IAM access control disabled.
Confirm both CreateDatabaseDefaultPermissions and CreateTableDefaultPermissions are empty arrays ([]).
If you plan to query S3 Tables from Amazon Redshift Query Editor V2, you must add the Amazon Redshift service-linked role as a Read-Only Admin in Lake Formation. Complete the following steps:
Important: Without this, Amazon Redshift Query Editor V2 doesn’t display external databases from s3tablescatalog. The Amazon Redshift service-linked role needs read-only admin access to browse the Data Catalog on behalf of users.
Create an IAM role that Lake Formation assumes to generate temporary, scoped credentials on behalf of users requesting access to S3 Tables data. Lake Formation uses this role (instead of its service-linked role) because Trusted Identity Propagation requires sts:SetContext in the trust policy, which is not available on the service-linked role. Without a custom role with this permission, Lake Formation cannot propagate the user’s IAM Identity Center identity when accessing S3 Tables.
Register the S3 Tables resource with Lake Formation using the data access role. This step lets Lake Formation manage access to S3 Tables through the Data Catalog and creates the s3tablescatalog federated catalog automatically.
Open the Lake Formation console and complete the following steps:
Figure 8: Lake Formation Catalogs page with the Enable S3 Table integration option.
Figure 9: Enable S3 Table integration dialog with the IAM role and external-engine access configured.
Important: Verify that the --role-arn matches the exact ARN of the role created in Step 2.2 (including the path). A mismatch (e.g., role/service-role/LFAccessRole-S3Tables vs role/LFAccessRole-S3Tables) will cause credential vending failures later.
Confirm the S3 Tables entry shows WithFederation: true and the correct role ARN.
Create an S3 table bucket and a namespace. Complete the following steps on the Amazon S3 console:
You can also perform these steps using the AWS Command Line Interface (AWS CLI). Refer to Creating a table bucket using the AWS CLI for equivalent commands.
After you remove default permissions, you need to give your Admin role explicit Lake Formation permissions to create tables. Because your Admin role is a Data Lake Admin, you can already see s3tablescatalog in the Amazon Athena console, but creating tables requires an explicit grant.
After this grant, you can create and insert data into tables from the Athena console.
Note: Your Admin role must be a Data Lake Admin (configured in Step 2.1) to browse s3tablescatalog in Athena. You need the explicit database grant for write operations (CREATE TABLE, INSERT).
Give your IAM Identity Center group access to query tables. This step enables Trusted Identity Propagation (TIP) for this group. When users in the group access data through TIP-integrated services like Amazon Redshift, Lake Formation evaluates their IAM Identity Center group membership and enforces table-level and column-level permissions accordingly.
Grant DESCRIBE on the database:
Grant SELECT and DESCRIBE on tables:
Tip: You can also configure column-level or row-level permissions for fine-grained access control. When granting on a specific table, additional options for Column permissions and Data filters become available.
You should see:
Connect to the Amazon Redshift cluster in us-west-2 as an admin user and create Redshift local tables. Grant permissions on those local resources to IAM Identity Center groups.
In the management account, navigate to the IAM Identity Center console and copy the AWS access portal URL (for example, https://d-1234560789.awsapps.com/start) from the dashboard.
Query the customer profile data through s3tablescatalog. Lake Formation enforces access based on Ethan’s IAM Identity Center group membership:
Figure 10: Query results from s3tablescatalog returned through Lake Formation in Amazon Redshift Query Editor V2.
This query reads customer profile data from Amazon S3 through Amazon Redshift Spectrum, with Lake Formation controlling who can access which tables and columns.
Run the UNLOAD command to write data from Amazon Redshift to the S3 bucket:
You don’t need an IAM role ARN in the command. S3 Access Grants handles authorization based on Ethan’s IAM Identity Center identity and group membership, propagated across Regions using IAM Identity Center Multi-Region support.
On the Amazon S3 console, navigate to s3://west-idc-amzn-s3-demo-bucket/awssso-sales/ and verify that the unloaded data files are present.
Combine customer profile data (queried via Lake Formation) with sales data (loaded via S3 Access Grants) using the shared customer_id column:
Figure 11: Joined results from S3 Tables and Amazon Redshift local data, ordered by sales amount.
This shows that you can join S3 Tables data with Amazon Redshift using the same IAM Identity Center identity.
To confirm that S3 Access Grants is enforcing access, try accessing a folder Ethan does not have a grant for:
This should return an access denied error, confirming that S3 Access Grants is controlling access based on the user’s identity and group membership.
You can verify that Amazon Redshift used both S3 Access Grants and Lake Formation for authorization by checking AWS CloudTrail:
Both event types show Ethan’s IAM Identity Center user identity, confirming trusted identity propagation works end-to-end for both access patterns.
The following table lists related blog posts and integration guides covering additional identity-based access patterns with Amazon Redshift. Although many of these were written for single-Region deployments, you can extend them to multi-Region environments by first enabling IAM Identity Center Multi-Region as described in Step 1 of this post. Use the table to find the guide that matches your identity provider and tooling:
When implementing this multi-Region architecture, keep the following operational and configuration considerations in mind. These reflect common challenges and design decisions encountered during deployment:
To avoid ongoing charges, clean up the resources created in this post:
In this post, we extended the Amazon Redshift and S3 Access Grants integration to a multi-Region setup using IAM Identity Center Multi-Region replication. We demonstrated two complementary data access patterns: SELECT through Lake Formation for fine-grained access control on S3 Tables data, and UNLOAD/COPY through S3 Access Grants for direct Amazon S3 access. Both patterns use the same IAM Identity Center identity for access control. We also showed how to set up a customer-managed multi-Region AWS KMS key, enable IAM Identity Center in an additional Region, configure Amazon S3 Tables with Lake Formation for identity-based access control using Trusted Identity Propagation, and replicate the complete S3 Access Grants setup in a different Region and account.
With this approach, AnyCompany Global’s analysts authenticate once and access data in any enabled Region while Lake Formation and S3 Access Grants enforce per-user, per-group access policies.
For additional guidance, refer to the following resources:
Maneesh is a Sr. Specialist Solutions Architect in Analytics at AWS, bringing more than 15 years of hands-on experience in designing and implementing large-scale data warehouse and analytics solutions. He collaborates closely with customers to help them build scalable, high-performance analytical data platforms.
Rohit is a Senior Analytics Specialist Solutions Architect at AWS based in Dallas, Texas. He has two decades of experience architecting, building, leading, and maintaining big data platforms. Rohit helps customers modernize their analytic workloads using the breadth of AWS services and ensures that customers get the best price/performance with utmost security and data governance.
Srividya is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.
Sandeep is a Senior Product Manager with Amazon SageMaker Lakehouse. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that help customers improve how they manage, secure, and access data.







